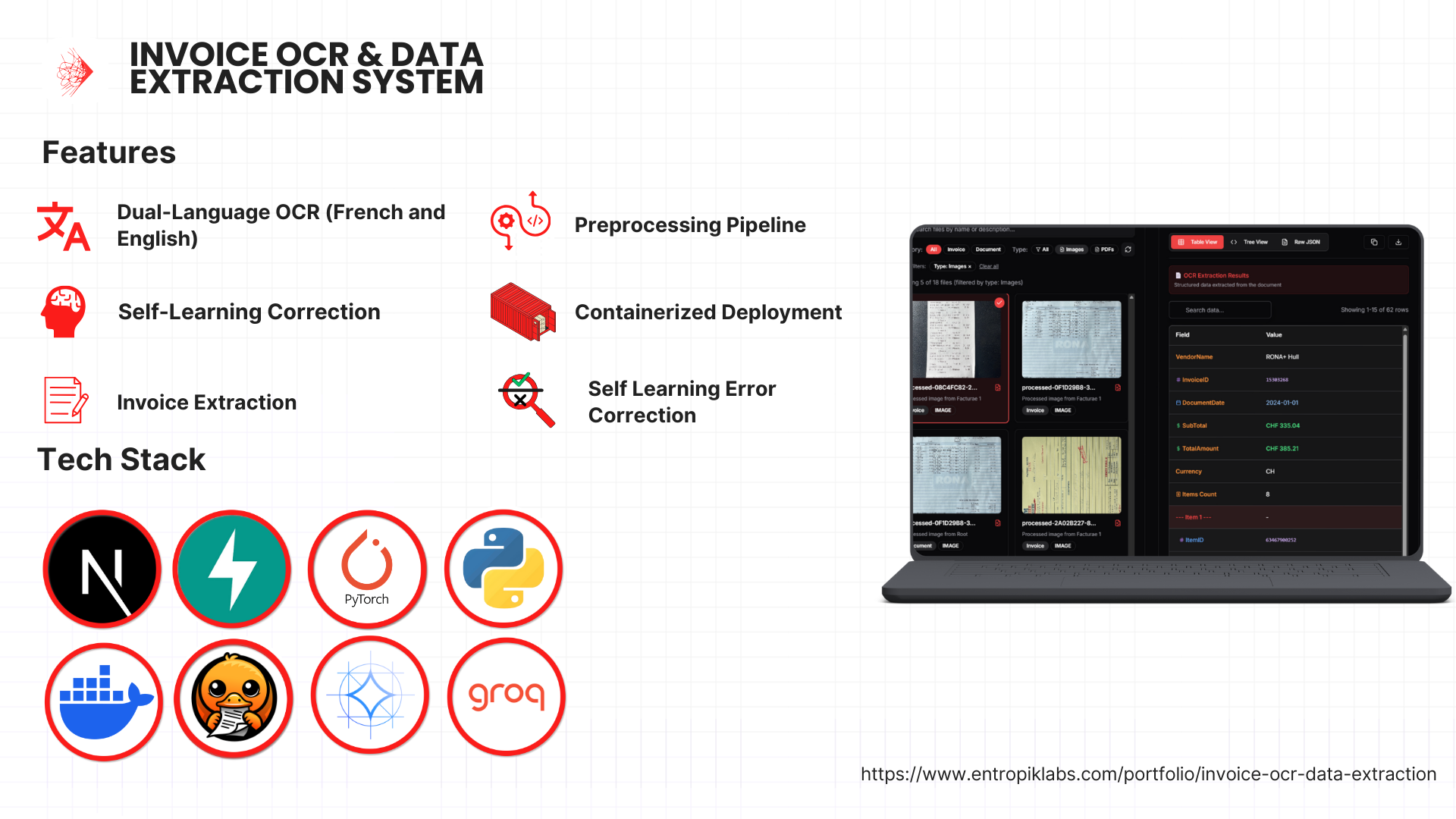
Project Overview
A lightweight, Dockerized OCR system to extract key invoice data from scanned PDFs and images. Designed for dual-language support (English/French), intelligent correction via Gemma LLM, and continuous self-learning.
The Challenge
We needed to ensure accurate data extraction across a variety of invoice layouts, languages, and file types without heavy infrastructure or retraining loops.
Our Solution
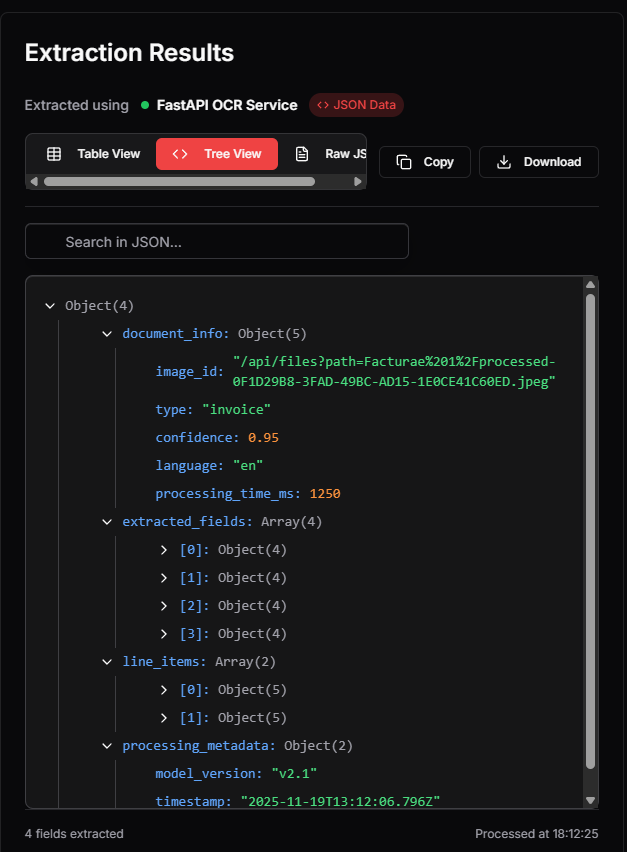
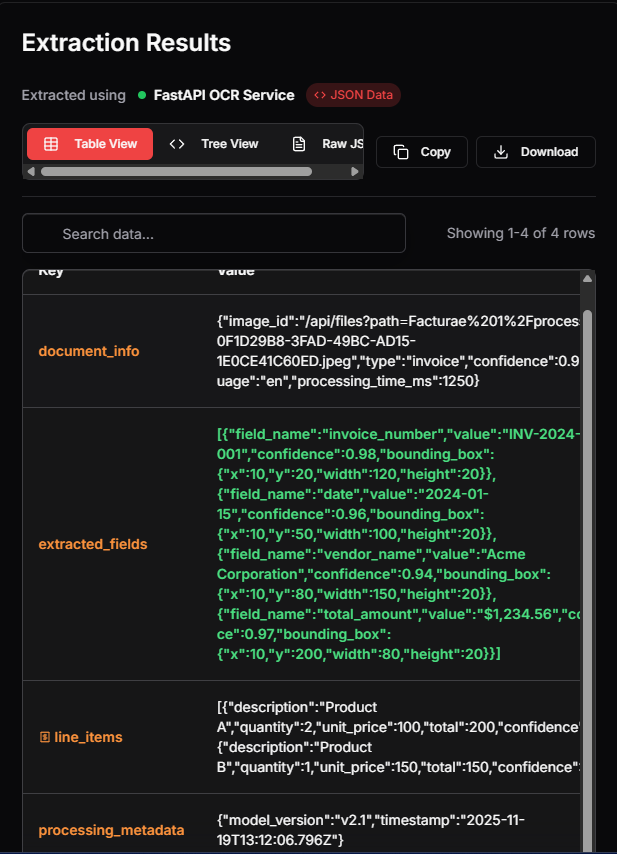
Implemented preprocessing using PyTorch and Docling OCR, combined with post-processing logic and a Gemma-based self-learning module. Delivered as a containerized FastAPI solution.
Key Features
Dual-Language OCR
Supports both English and French invoices using Docling's multilingual capabilities and automatic language detection.
Preprocessing Pipeline
Enhances OCR quality through contouring, contrast correction, and DPI normalization using PyTorch.
Self-Learning Correction
Uses Gemma LLM to track corrections, build correction maps, and improve output over time without retraining.
Technical Challenges & Solutions
Variable Document Layouts
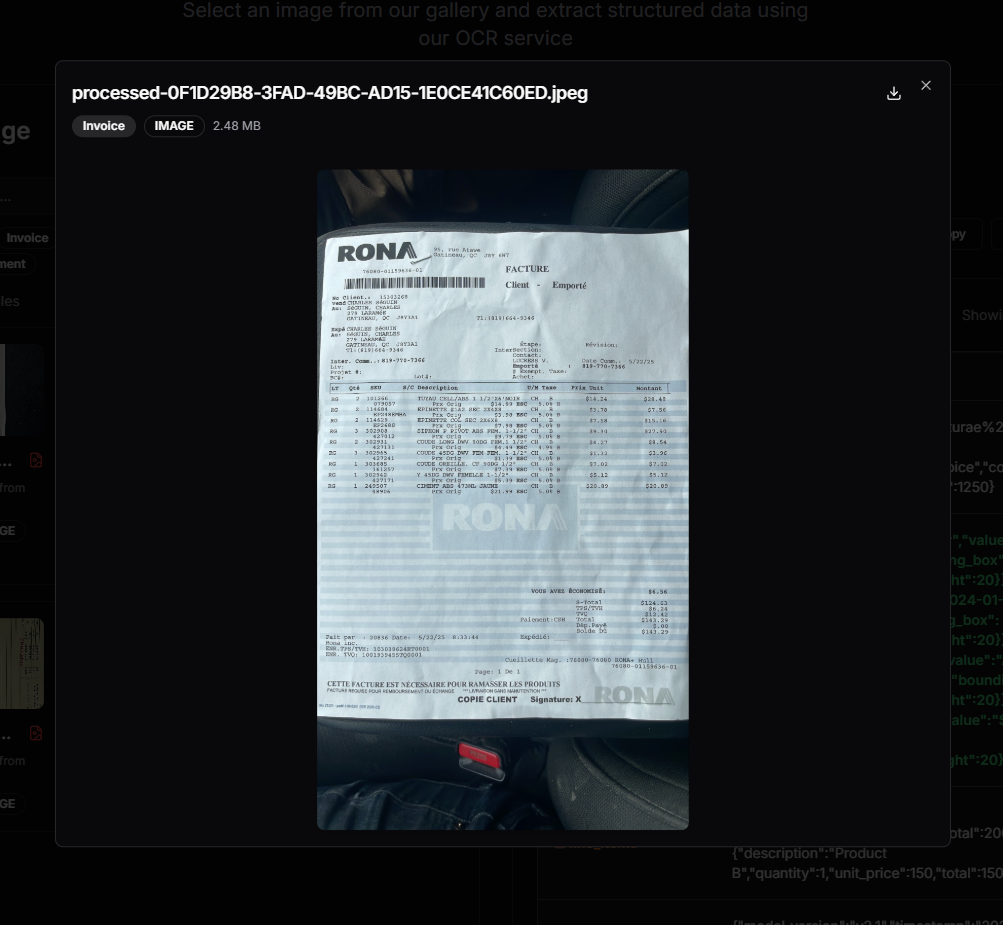
Invoices came in a variety of formats, languages, and image qualities.
Solution: Built a layout-agnostic preprocessing and extraction logic using Docling, regex, LLM, and heuristics.
Low OCR Confidence Scores
OCR struggled with uncommon fonts, low DPI, and multilingual content.
Solution: Implemented fallback logic with language detection, spelling correction, and field-level rule checks.
No Retraining Infrastructure
Client needed learning capabilities but lacked infrastructure for retraining models.
Solution: Delivered a correction module based on rule accumulation via user feedback loops.
Project Timeline
Pipeline Implementation & Demo
Built and demoed complete preprocessing and OCR pipeline
Final Delivery
Finalized containerized deployment with intelligent corrections
Self-Learning Module
Integrated correction-feedback loop for long-term accuracy improvement
Key Results
Technologies Used
Before vs After
Client Testimonial
"The Entropik team delivered exactly what we needed, a highly adaptable and accurate OCR pipeline with smart correction capabilities. It integrates seamlessly into our stack while consuming minimum resources and cost."